BM25S⚡
BM25S (or BM25-Sparse) is a fast and efficient implementations of BM25 algorithms in Python, built on top of Numpy and Scipy.| 💻 GitHub | 🏠 Homepage | 🤗 Blog Post | 📝 Technical Report |
Motivation
BM25S is designed to provide a fast, low-dependency and low-memory implementation of BM25 algorithms in Python. It is solely built with Numpy and Scipy, with optional dependencies for stemming and selection, as well as integrations to Huggingface Hub, allowing you to share and use other BM25 indices with ease.
By having minimal dependencies, bm25s allows everything to happen inside Python in just a few lines. However, thanks to a novel sparse eager computation strategy, bm25s is able to achieve speeds comparable or exceeding ElasticSearch, all while eliminate the need for setting up web servers, installing & running Java, and relying on abstracted APIs.
Additionally, we also ship with a tokenizer (called with bm25s.tokenize()), which is fast but also very simple to extend thanks to its purely Python-based implementation (although you might observe slight performance decrease on certain datasets compared to advanced analyzers found in ElasticSearch).
You can find below a relative speed up of BM25S and Elastic with respect to rank-bm25 (single-threaded setting), the most popular BM25 implementation in Python. The speed up is calculated as the ratio of the queries per second with respect to rank-bm25, on 5 popular datasets from BEIR.
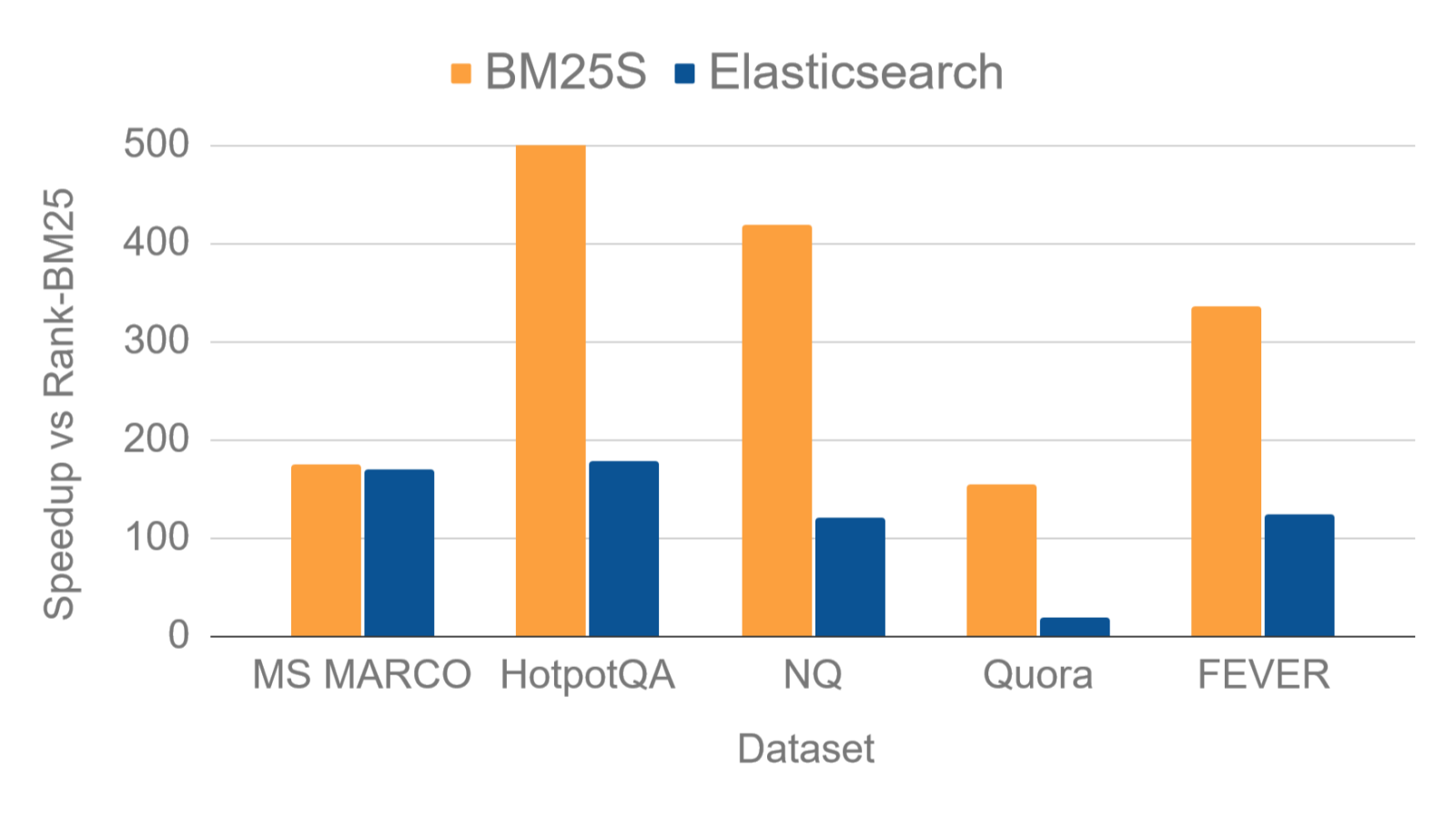
Quickstart
First, you can install it with pip:
# Install with all extra dependencies
pip install bm25s[full]
import bm25s
# Create your corpus here
corpus = [
"a cat is a feline and likes to purr",
"a dog is the human's best friend and loves to play",
"a bird is a beautiful animal that can fly",
]
# Tokenize the corpus and index it
corpus_tokens = bm25s.tokenize(corpus)
retriever = bm25s.BM25(corpus=corpus)
retriever.index(corpus_tokens)
# You can now search the corpus with a query
query = "does the fish purr like a cat?"
query_tokens = bm25s.tokenize(query)
docs, scores = retriever.retrieve(query_tokens, k=2)
print(f"Best result (score: {scores[0, 0]:.2f}): {docs[0, 0]}")
# Happy with your index? Save it for later...
retriever.save("bm25s_index_animals")
# ...and load it when needed
ret_loaded = bm25s.BM25.load("bm25s_index_animals", load_corpus=True)
Which BM25?
You can find out which variant you are using by calling retriever.method.
You can use the following variants of BM25 in bm25s (see Kamphuis et al. 2020 for more details):
- Robertson et al. (
method="robertson") - ATIRE (
method="atire") - BM25L (
method="bm25l") - BM25+ (
method="bm25+") - Lucene (
method="lucene")
Comparison
Below are some more comprehensive benchmarks comparing bm25s to other popular BM25 implementations. We compare the following implementations:
bm25s: Our implementation of BM25 in pure Python, powered by Scipy sparse matrices.rank-bm25(Rank): A popular Python implementation of BM25.bm25_pt(PT): A Pytorch implementation of BM25.elasticsearch(ES): Elasticsearch with BM25 configurations.
OOM means the implementation ran out of memory during the benchmark.
Extremely fast retrieval
bm25s is very fast and efficient thanks to a novel eager computation strategy, leveraging scipy’s sparse matrices for efficient storage and fast computation. Here are the results of the benchmark on 5 popular datasets from the BEIR benchmark, measured in queries per second on a single threaded CPU:
| Dataset | BM25S | Elastic | BM25-PT | Rank-BM25 |
|---|---|---|---|---|
| msmarco | 12.20 | 11.88 | OOM | 0.07 |
| fever | 20.19 | 7.45 | OOM | 0.06 |
| hotpotqa | 20.88 | 7.11 | OOM | 0.04 |
| nq | 41.85 | 12.16 | OOM | 0.10 |
| quora | 183.53 | 21.80 | 6.49 | 1.18 |
| scifact | 952.92 | 20.81 | 184.30 | 47.60 |
The full table can be found in the GitHub repository. More detailed benchmarks can be found in the bm25-benchmarks repo.
Minimal package size
bm25s is designed to be lightweight. This means the total disk usage of the package is minimal, as it only requires wheels for numpy (18MB), scipy (37MB), and the package itself is less than 100KB. Here’s the uncompressed disk usage of the packages within a virtual environment:
| Package | Disk Usage |
|---|---|
rank-bm25 |
99MB |
bm25s (ours) |
479MB |
elastic |
1183MB |
bm25_pt |
5346MB |
Optimized RAM usage
bm25s allows considerable memory saving through the use of memory-mapping, which allows the index to be stored on disk and loaded on demand.
When testing with 6 arbitrary queries with an index built with MS MARCO (8.8M documents, 300M+ tokens), we have the following:
| Method | Load Index (s) | Retrieval (s) | RAM usage (GB) |
|---|---|---|---|
| Memory-mapped | 0.62 | 0.18 | 0.90 |
| In-memory | 11.41 | 0.74 | 10.56 |
When you run bm25s on 1000 queries on the Natural Questions dataset (2M+ documents), the memory usage is over 50% lower than the in-memory version with trivial difference in speed. You can find more information in the GitHub repository.
Does this replace ElasticSearch?
bm25s is not a replacement for ElasticSearch, but a lightweight and efficient alternative for BM25 ranking. It is designed to be used in scenarios where you need to rank documents based on BM25 scores, but do not need the full capabilities of ElasticSearch. It is particularly useful for research and development, where you need to quickly prototype BM25-based ranking algorithms, and need to specify the BM25 parameters, algorithm, and tokenization process as precisely as possible. On the other hand, ElasticSearch is a full-fledged search engine that provides a wide range of features, including monitoring, scaling, and distributed search capabilities, and extend to non-lexical search methods. Moreover, the results for ElasticSearch sometimes exceed pure BM25 implementations due to advanced analyzers being used by default.
Citation
If you use bm25s in your work, please use the following bibtex:
@misc{bm25s,
title={BM25S: Orders of magnitude faster lexical search via eager sparse scoring},
author={Xing Han Lù},
year={2024},
eprint={2407.03618},
archivePrefix={arXiv},
primaryClass={cs.IR},
url={https://arxiv.org/abs/2407.03618},
}